语料在导入到正式表以后,在进行自然语言处理之前需要做适当的语料清洗。清洗后的语料将会变得更加“干净”并有利于后期分析。这些均由C#函数来实现。
语料清洗的总体目的有如下几点:
(1)清理空白字符
清理空白字符的目的就是:将不可见字符或空格字符更换成单一的空格字符。
public static bool IsInvisible(char cValue)
{
// Unicode不可见区域
switch ((int)cValue)
{
case 0x1680:
case 0x180E:
case 0x2028:
case 0x2029:
case 0x202F:
case 0x205F:
case 0x2060:
case 0x3000:
case 0xFEFF:
return true;
}
// Unicode不可见区域
if (cValue >= 0xD7B0 &&
cValue <= 0xF8FF) return true;
// Unicode不可见区域
if (cValue >= 0xFFF0 &&
cValue <= 0xFFFF) return true;
// Unicode不可见区域
if (cValue >= 0x2000 &&
cValue <= 0x200D) return true;
// 返回结果
return cValue < 32 || cValue == 0x7F;
}
注意:不要随意删除空格和不可见字符。否则,可能会引起语料的语义发生明显变化。
public static string ClearInvisible(string strValue)
{
// 将不可见字符替换成空格
return Regex.Replace(strValue, @"([\x00-\x1F]|\x7F|\u1680|\u180E|[\u2000-\u200D]|[\u2028-\u2029]|\u202F|[\u205F-\u2060]|\u3000|[\uD7B0-\uF8FF]|\uFEFF|[\uFFF0-\uFFFF])+", " ");
}
(2)将全角字符更换成半角字符
全角字符统一至半角字符之后,更有利于程序处理。
需要注意的是:不是所有的符号都能转换成半角的。例如:全角的正反双引号是没有对应的半角字符。
public static string NarrowConvert(string strValue)
{
// 全角转半角
//return Strings.StrConv(strValue.Value, VbStrConv.Narrow, 0);
// 创建字符串
StringBuilder sb = new StringBuilder(strValue.Length);
// 循环处理
foreach (char cValue in strValue)
{
// 特殊处理
if (cValue == 12288) sb.Append(' ');
// 检查字符范围
else if (cValue < 65281) sb.Append(cValue);
else if (cValue > 65374) sb.Append(cValue);
// 转换成半角
else sb.Append((char)(cValue - 65248));
}
// 返回结果
return sb.ToString();
}
public static string WideConvert(string strValue)
{
// 半角转全角
//return Strings.StrConv(strValue.Value, VbStrConv.Wide, 0);
// 创建字符串
StringBuilder sb = new StringBuilder(strValue.Length);
// 循环处理
foreach (char cValue in strValue)
{
// 特殊处理
if (cValue == 32) sb.Append((char)12288);
// 检查字符范围
else if (cValue < 33) sb.Append(cValue);
else if (cValue > 126) sb.Append(cValue);
// 转换成全角
else sb.Append((char)(cValue + 65248));
}
// 返回结果
return sb.ToString();
}
(3)XML反转义
XML反转义也就是将转义的字符,还原成原始字符。例如: 对应着空格。更为复杂一点的是“&#”开头和“&x”开头的转义字符。需要通过获得10进制或者16进制数值进行还原。
public static string XMLUnescape(string strValue)
{
// 记录日志
//Log.LogMessage("XML", "XMLUnescape", "开始反转义!");
// 创建词典
Dictionary<string, string> escapes = new Dictionary<string, string>();
// 匹配循环
foreach (Match item in Regex.Matches(strValue, @"&#[0-9|o|O|l]{1,5};"))
{
// 记录日志
//Log.LogMessage("XML", "XMLUnescape", item.Value);
int value = 0;
// 获得数字部分
string strNumber =
item.Value.Substring(2, item.Value.Length - 3);
// 检查结果
if (strNumber.IndexOfAny(errors) >= 0)
{
// 将l替换成1
strNumber = strNumber.Replace("l", "1");
// 将o替换成0
strNumber = strNumber.Replace("o", "0");
// 将O替换成0
strNumber = strNumber.Replace("O", "0");
}
// 尝试解析
value = System.Convert.ToInt32(strNumber);
// 加入词典
if (!escapes.ContainsKey(item.Value))
escapes.Add(item.Value, new string((char)value, 1));
}
// 匹配循环
foreach (Match item in Regex.Matches(strValue, @"&#[x|X]([0-9|a-f|A-F|o|O|l]{1,4});"))
{
// 记录日志
//Log.LogMessage("XML", "XMLUnescape", item.Value);
int value = 0;
// 获得数字部分
string strNumber =
item.Value.Substring(3, item.Value.Length - 4);
// 检查结果
if (strNumber.IndexOfAny(errors) >= 0)
{
// 将l替换成1
strNumber = strNumber.Replace("l", "1");
// 将o替换成0
strNumber = strNumber.Replace("o", "0");
// 将O替换成0
strNumber = strNumber.Replace("O", "0");
}
// 转换
value = System.Convert.ToInt32(strNumber, 16);
// 加入词典
if (!escapes.ContainsKey(item.Value))
escapes.Add(item.Value, new string((char)value, 1));
}
// 开始替换
foreach (KeyValuePair<string, string> kvp in escapes)
{
// 执行替换操作
strValue = strValue.Replace(kvp.Key, kvp.Value);
}
// 将字符串转义还原
foreach (string[] item in ESCAPES)
{
// 执行替换操作
if (strValue.Contains(item[0])) strValue = strValue.Replace(item[0], item[1]);
}
// 记录日志
//Log.LogMessage("XML", "XMLUnescape", "反转义结束!");
// 返回结果
return strValue;
}
考虑到原始数据可能多次经过HTML转义,因此以上三个步骤需要反复执行,直至内容不再发生变化为止。
注意:代码之中选择性地对小写字母o、大写字母O,小写字母l做处理,是源于实际数据的混乱。很多网络文本数据会将这三个字母当0和1。
(4)替换
替换的目的:就是利用正则匹配规则将符合规则的字符串替换成其他字符串。一般用于清理多余的标点符号,或者不符合规格的符号标记。这些替换规则可以存储于数据表中。在系统加载前,全部装入内存之中,以加快处理速度。
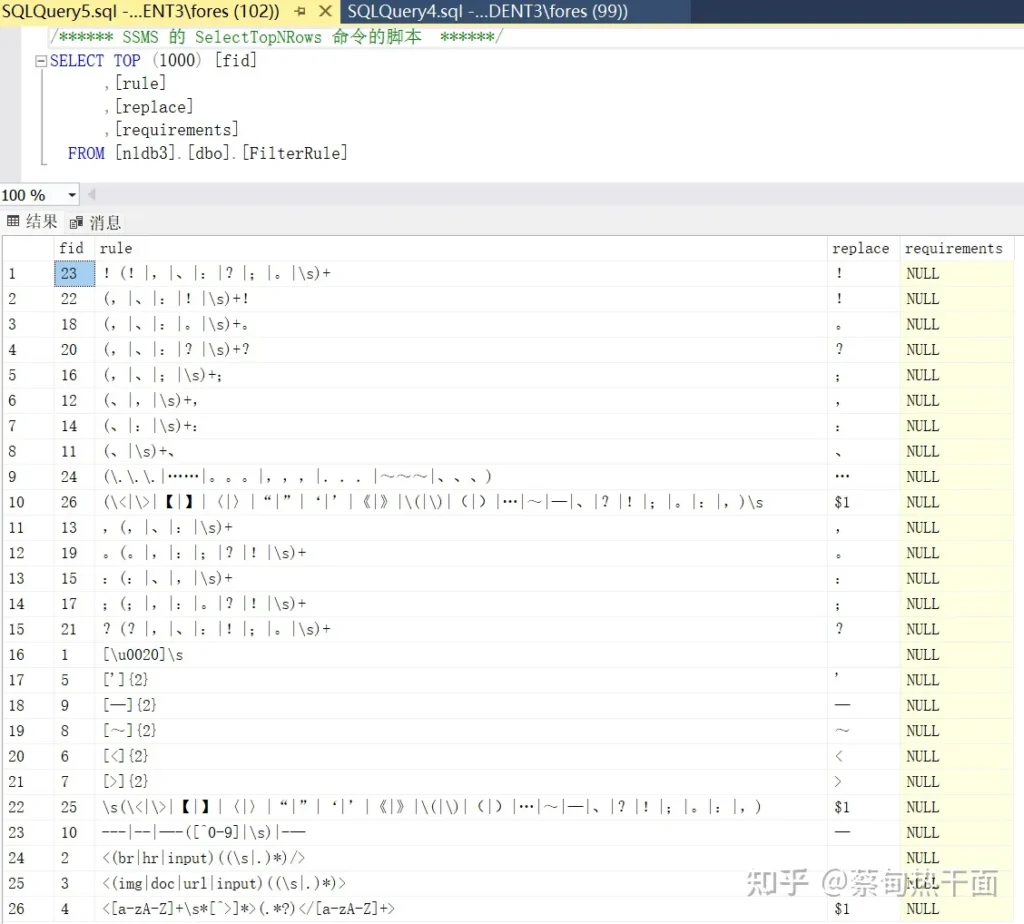
替换规则也是需要进行反复执行,直至内容不再发生改变为止。
这些规律也可以直接固化在程序之中。
// 过滤规则
private static readonly string[][] FILTER_RULES =
{
new string[] {"(\\u0020)\\s", " "},
new string[] {"('){2,}", "'" },
new string[] {"(`){2,}", "`" },
new string[] {"(<){2,}", "<" },
new string[] {"(>){2,}", ">" },
new string[] {"(-){2,}", "—" },
new string[] {"(、){2,}", "、" },
new string[] {"(~){2,}", "~" },
new string[] {"(—){2,}", "—" },
new string[] {"(…){2,}", "…" },
new string[] {"(\\.){3,}", "…" },
new string[] {",(,|:|\\s)*,", "," },
new string[] {",(,|:|\\s)*:", ":" },
new string[] {",(,|:|\\s)*。", "。" },
new string[] {",(,|:|\\s)*;", ";" },
new string[] {",(,|:|\\s)*?", "?" },
new string[] {",(,|:|\\s)*!", "!" },
new string[] {":(,|:|\\s)*,", ":" },
new string[] {":(,|:|\\s)*:", ":" },
new string[] {":(,|:|\\s)*。", "。" },
new string[] {":(,|:|\\s)*;", ";" },
new string[] {":(,|:|\\s)*?", "?" },
new string[] {":(,|:|\\s)*!", "!" },
new string[] {"。(,|:|。|;|?|!|\\s)+", "。" },
new string[] {";(,|:|。|;|?|!|\\s)+", ";" },
new string[] {"?(,|:|。|;|?|!|\\s)+", "?" },
new string[] {"!(,|:|。|;|?|!|\\s)+", "!" },
new string[] {"<(br|hr|input)((\\s|\\.)*)/>", " " },
new string[] {"<(img|doc|url|input)((\\s|\\.)*)>", " " },
new string[] {"<[a-zA-Z]+\\s*[^>]*>(.*?)</[a-zA-Z]+>", "$1" },
new string[] {"\\s(\\<|\\>|【|】|〈|〉|“|”|‘|’|《|》|\\(|\\)|(|)|[|]|{|}|…|~|—|、|?|!|;|。|:|,)", "$1" },
new string[] {"(\\<|\\>|【|】|〈|〉|“|”|‘|’|《|》|\\(|\\)|(|)|[|]|{|}|…|~|—|、|?|!|;|。|:|,)\\s", "$1" }
};
经过以上处理,原始语料算是初步清理干净,可以进行下一步的操作。
清洗函数工作效率并不是很高。为了加快处理速度,建议将过滤后的数据再另存至一张数据表中。其他后续的工作,都依据过滤后的数据进行处理。
在文章的结尾介绍一下两个C#库,后面会被经常使用到。
(1)using Microsoft.VisualBasic;
该库主要涉及简体繁体相互转换,半角和全角的相互转换。
public static string TraditionalConvert(string strValue)
{
// 转繁体
return Strings.StrConv(strValue, VbStrConv.TraditionalChinese, 0);
}
public static string SimplifiedConvert(string strValue)
{
// 转简体
return Strings.StrConv(strValue, VbStrConv.SimplifiedChinese, 0);
}
(2)using System.Text.RegularExpressions;
该库主要涉及基于正则表达式的匹配和替换。
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlString RegExMatch(SqlString pattern, SqlString input)
{
// 检查参数
if(input.IsNull || pattern.IsNull) return String.Empty;
// 返回匹配结果
return Regex.Match(input.Value, pattern.Value, RegexOptions.None).Value;
}
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlBoolean RegExIsMatch(SqlString pattern, SqlString input)
{
// 检查参数
if (input.IsNull || pattern.IsNull) return SqlBoolean.False;
// 返回匹配结果
return Regex.IsMatch(input.Value, pattern.Value, RegexOptions.None);
}
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlInt32 RegExIndex(SqlString pattern, SqlString input)
{
// 检查参数
if (input.IsNull || pattern.IsNull) return -1;
// 返回匹配结果
return Regex.Match(input.Value, pattern.Value, RegexOptions.None).Index;
}
[Microsoft.SqlServer.Server.SqlFunction
(DataAccess = DataAccessKind.Read,
FillRowMethodName = "RegExSplit_FillRow",
TableDefinition = "SplitValue nvarchar(4000)")]
public static IEnumerable RegExSplit(SqlString pattern, SqlString input)
{
// 检查参数
if (input.IsNull || pattern.IsNull) return null;
// 返回结果
return Regex.Split(input.Value, pattern.Value, RegexOptions.None);
}
[Microsoft.SqlServer.Server.SqlFunction]
public static SqlString RegExReplace(SqlString pattern, SqlString input, SqlString replacement)
{
// 检查参数
if (input.IsNull || pattern.IsNull) return SqlString.Null;
// 返回匹配结果
return Regex.Replace(input.Value, pattern.Value, replacement.Value, RegexOptions.None);
}
[Microsoft.SqlServer.Server.SqlFunction
(DataAccess = DataAccessKind.Read,
FillRowMethodName = "RegExMatches_FillRow",
TableDefinition = "MatchValue nvarchar(4000), MatchIndex int, MatchLength int")]
public static IEnumerable RegExMatches(SqlString pattern, SqlString input)
{
// 检查参数
if (input.IsNull || pattern.IsNull) return null;
// 返回结果
return Regex.Matches(input.Value, pattern.Value, RegexOptions.None);
}
注意:C#的参数顺序和VB的参数顺序不一致。另外VB的数组索引从1起,而C#是从0起。