在本章节中,作者主要是探讨NLP中非常基础的一个问题:词频统计(Term Frequency)。这个问题是很多NLP分析和处理的基础。弄清楚这个问题,有助于了解NLP处理中的问题和难点。
后续的内容主要基于对NLP的讨论,会涉及汉语语法的一些内容。更多地,还是在计算机算法领域去讨论相关问题。语法相关的内容,也是汉语规律的部分总结,实际算法应用时应当借鉴,而不是受其约束。
一、定义
在一份给定的文件里,词频(Term Frequency,TF)指的是某一个给定的词语在该文件中出现的次数。定义虽然简单,但是涉及很多问题。这些问题也涉及到NLP处理中的问题和难点。
(1)词的定义
在汉语中,词可以定义为能表达一个相对完整的意义或者具有某一特定功用的字符串。例如:“花朵”则表达了一个事物;“美丽”则表达了一个状态;“的”则代表了一个功用。
词长度(即字符串的长度)可长,可短。在汉语中,最短的词也就一个字,长的词可能像四字成语,或者更长的习惯用语。现代白话文是从古代文言文发展而来。古代文言文中很多词是以单字表意,这个特征在现代白话文中也依然保留了不少。
(2)字面组合与实际意义的差别
由于汉语的特点,存在很多字面组合与实际意义不符的情况。例如:“我在意大利旅游。”和“我在意大利这个人。”作为人是可以理解:这两句话中的“在意大利”的意思是不一样的。前者中“在意大利”表明是所处的位置;后者“在意大利”表明在意被称为“大利”的这个人。这个例子不一定恰当,但是这种情况在汉语中,是普遍存在的一种情况。计算机是无法“直接理解”这个差别的,它只能比较数与数之间的差异。
就目前的NLP技术处理能力,分词处理都存在很多问题。要想细致准确地按照实际意义去统计是不现实的,更多情况是按照字面上的字符串去统计词频。以上两个句子为例,那么计算机只认“在意大利”这个字符串,实际上的意义区别就被忽略掉了。或者说:相同的字符串,都被计算机认为是同一个词。
二、语料的影响
词频统计是依据语料进行统计。语料有长有短,有多有少,有来源倾向。这些都会导致每次统计结果会有很大差异。这种差异既有好处,也有坏处。好处是利于某单一语料特征的分析;坏处是不利于形成对汉语所有词语词频的把握,也不利于后续进一步的应用。
- 语料的过短或者过少,那么有很多词汇不会出现在统计结果中。
- 语料的长短不一,词汇出现的频次会有所不同。
- 语料的来源,会导致某一类词汇出现的次数会偏高(或者偏低)。
另外,以目前的技术能力,在实际的NLP应用过程中,是不可能随时进行词频统计。更多实际情况是会预先建立一个词汇表,根据这个词汇表对指定的语料进行词频统计。这个指定的语料库必须十分庞大,来源丰富,从而保证词频统计具有相对准确性。
三、词典的影响
在词典中指定的词语,一般是具有一定意义的字符串。虽然无法完全按照准确词意去进行统计,但是至少可以保证统计具有一定正面意义。即实际统计出的结果应和逻辑中的“准确结果”成正比。
在这些指定的词当中,会出现的一个明显的问题,就是相互“重叠”的问题。例如:“在意”和“在意大利”这两个词就出现了相互重叠问题。那么“在意大利”这个词出现一次,“在意”也会被统计一次;反之则不然。这样的重叠或者部分重叠情况还有很多。如果需要准确统计,则自然是先分词,再统计。但分词的算法也未得到准确解决。因此,在实际应用的初级阶段,需要跳过分词这个问题,先简单地从字面进行统计。
另外,如果指定了一个明确的词典,很明显:新词的抽取就不能依赖这个词典所做的词频统计。
四、统计的方法
统计的方法其实很简单:每条语料,逐字扫描。即,给定一个窗口宽度W,从某条语料中取出一段字符串,并在词典中查询是否有对应的词条。如果有对应的词条,那么该词条的计数器加一。这个窗口宽度W,最小为1,最长为字典词条的最大长度。
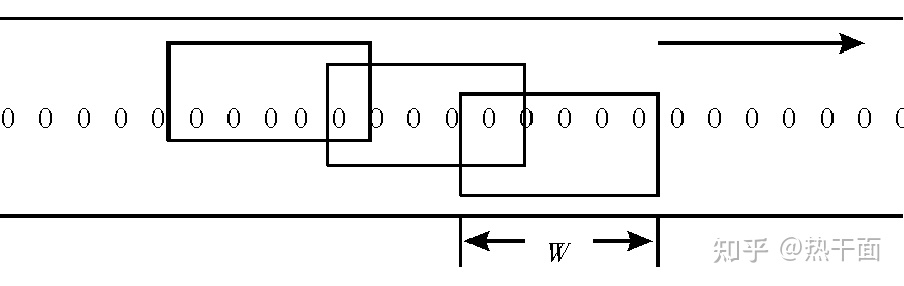
如果采用先分词,再进行词频统计,那么这个词频统计会因分词算法的不准确性,导致一定的误差。这个误差的主要原因是正向分词算法(FMM)和逆向分词算法(BMM)在分词的时候,可能会产生词汇分法上的差异,而且这个差异还跟词典有一定关系。此时,正向分词统计和逆向分析统计的结果会有一定不同。
例如:“在此前”这个短语,正向分词算法会将其分词成“在此”和“前”,而逆向分词算法会将其分词成“在”和“此前”。这样会导致分词后的词汇的词频产生不同的差异。例子中的这种情况,在汉语中很普遍。
这个差异的大小也取决于词典的状态:词典定义得“不好”,这个差异会被放大;词典定义得“好”,这个差异相对就比较小。这里的词典定义得“好”与“不好”很大程度上,又与个人得阅读习惯有关。
词频统计是否正确的判断标准:请参考“相关系数”的基本性质2。而且这个判断准则与字符串的分割方式无关。
由于字符串\(s\)由子字符串集合\(\{s_1,s_2,……,s_N\}\)按顺序拼接而得。所以字符串\(s\)所对应的频次不可能超过任何一个子字符串集合元素的统计频次。
五、统计结果分析
统计结果中最显著的特点:
- 随着词条字符串长度的增加,词频下降。这个特点可以用概率去解释,读者可以自行研究。
- 虚词的词频比较高,拥有较小的族群;实词的词频比较低,但是拥有庞大的族群。这个结果可以用信息熵去解释。
下面是作者搜集到的词典库的统计概况:
表(5-1)词典中字符串长度分布概况
| 统计对象 | 统计类别 | 统计数量 |
|---|---|---|
| Dictionary.length | 2-4 | 6432510 |
| Dictionary.length | 8-16 | 4966276 |
| Dictionary.length | 4-8 | 4160586 |
| Dictionary.length | 1-2 | 2062030 |
| Dictionary.length | 16-32 | 25532 |
| Dictionary.length | 32-64 | 111 |
表(5-2)词典中词频统计分布概况(主动关闭或者未能出现的词条不算在内)
| 统计对象 | 统计类别 | 统计数量 |
|---|---|---|
| Dictionary.count | 百余次 | 516418 |
| Dictionary.count | 十余次 | 475038 |
| Dictionary.count | 千余次 | 328653 |
| Dictionary.count | 单次 | 177801 |
| Dictionary.count | 万余次 | 97791 |
| Dictionary.count | 十万余次 | 18489 |
| Dictionary.count | 百万余次 | 3789 |
| Dictionary.count | 千万余次 | 387 |
表(5-3)词典中部分词条的词频
| 词条 | 词频 | 词条 | 词频 |
|---|---|---|---|
| 0 | 8811627 | 公司 | 922412 |
| 1 | 6395984 | 华硕 | 858920 |
| 一 | 6381555 | 产品 | 595435 |
| 2 | 5505122 | 企业 | 426484 |
| 在 | 5161562 | 表示 | 425054 |
| 是 | 4867834 | 投资 | 418194 |
| 有 | 4176046 | 北京 | 375065 |
| 人 | 4120918 | 问题 | 347133 |
| 中 | 3852293 | 美国 | 323157 |
| 上 | 3454016 | 银行 | 320078 |
注:有关数字“0”,“1”,“2”以及“华硕”这样的词条上榜,很明显是受到了语料来源的影响。
六、其他相关问题
首先,词频\(F\)与词语出现的概率\(P\)成正比。
\[P=\frac{F}{C}\]
这里\(C\)代表某种统计方法下,所有词汇出现的次数总和。一般情况下,对一个庞大的语料库,这个\(C\)值会非常大,而\(P\)会非常小。如果只是单纯比较词与词之间在某种统计方法下的词频差距,那么完全可以把这个\(C\)作为常数,而忽略其实际值。这样有利于简化计算,而且不用绞尽脑汁去计较\(C\)值应该为多少(因为所有词频都是在同一种统计方法下)。
其次,词频\(F\)与信息熵\(H\)成反比。
\[H=-log_2 P = -log_2 \frac{F}{C}=\frac{1}{ln2} \cdot (lnC -lnF) \cong 1.4427 \times (lnC -lnF)\]
举一个实际例子:
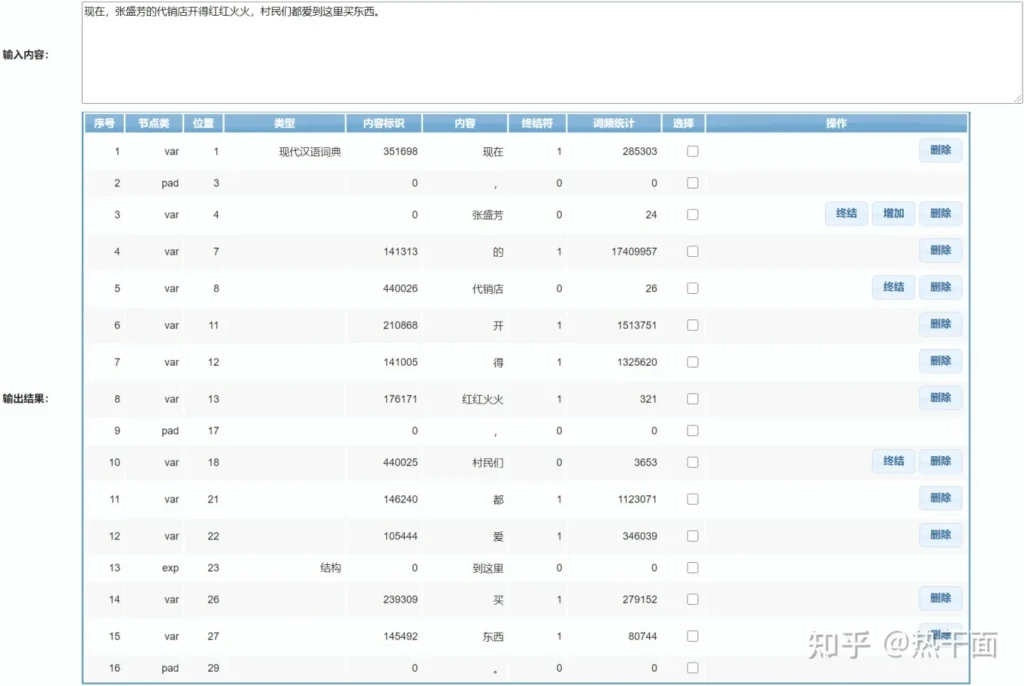
上图中,是一个实际语料句子的分词结果。可以对比词汇内容和从词频统计这一栏可以得到一些初步结论:
- 在一个分句中(句内标点符号之间的内容),词汇所传递“传递意义的重要性”和词频成反比。以“张胜芳的代销店开得红红火火”为例,按照词频统计排个序,那么依次出现的词汇应该是:“张盛芳”,“代销店”,“红红火火”,“得”,“开”,“的”。这个句子的主体意思基本通过前面三个词就能表达。
- 词频高的词,基本是虚词,充当句子结构的词;词频较低的词,基本是实词,是传递实际意义的词。
以上两点其实就是信息熵和词频成反比的具体体现。
最后总结以下词频\(F\)的几个关键点:
- 词频统计是NLP的重要基础:信息熵,词概率等参数均只是词频的一个映射变换,但是用于分析的实质基础未发生变化。
- 以手工方法建立词典,则需要大量人工去维护这个词典。因此基于词典的算法都脱离不了人。如果需要计算机能自我确定新词,除去旧词,建立符合人类阅读习惯的一套NLP机制,则词频统计和分析是必须要使用的方法。
- 对于人类的语言词汇没有绝对的事情可言,永远是处于实际社会环境的变化当中,人工维护的词典跟踪这个变化趋势会有一定难度,只能作为辅助手段,更重要的还是需要基于词频统计和分析。
六、SQLServer代码
下面附上词频统计的代码,供参考。
USE [nldb]
GO
-- ================================================
-- Template generated from Template Explorer using:
-- Create Procedure (New Menu).SQL
--
-- Use the Specify Values for Template Parameters
-- command (Ctrl-Shift-M) to fill in the parameter
-- values below.
--
-- This block of comments will not be included in
-- the definition of the procedure.
-- ================================================
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
-- =============================================
-- Author: <罗堃>
-- Create date: <2020年12月17日>
-- Description: <从语料库中统计内容的发生次数>
-- =============================================
CREATE OR ALTER PROCEDURE [统计字典词频]
-- Add the parameters for the stored procedure here
@SqlCount INT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
-- 声明临时变量
DECLARE @SqlTID INT;
DECLARE @SqlLength INT;
DECLARE @SqlText UString;
DECLARE @SqlPosition INT;
DECLARE @SqlCheckLength INT;
DECLARE @SqlStatisticCount INT;
DECLARE @SqlRightText UString;
DECLARE @SqlLeftContent UString;
-- 打印空行
PRINT '统计字典词频> 加载' + CONVERT(NVARCHAR(MAX), @SqlCount) + '条记录!';
-- 获得最大长度
SELECT @SqlLength = MAX(length) FROM dbo.Dictionary WHERE [enable] = 1;
-- 声明游标
DECLARE SqlCursor CURSOR
STATIC FORWARD_ONLY LOCAL FOR
SELECT TOP (@SqlCount) tid, content
FROM dbo.TextPool WHERE parsed = 0;
-- 打开游标
OPEN SqlCursor;
-- 取第一条记录
FETCH NEXT FROM SqlCursor INTO @SqlTID, @SqlText;
-- 循环处理游标
WHILE @@FETCH_STATUS = 0
BEGIN
-- 设置初始值
SET @SqlPosition = 0;
SET @SqlStatisticCount = 0;
-- 循环处理
WHILE @SqlPosition < LEN(@SqlText)
BEGIN
-- 修改计数器
SET @SqlPosition = @SqlPosition + 1;
-- 获得剩余右侧内容
SET @SqlRightText = RIGHT(@SqlText, LEN(@SqlText) - @SqlPosition + 1);
-- 设置初始值
SET @SqlCheckLength = 0;
-- 循环处理
WHILE @SqlCheckLength < @SqlLength AND
@SqlPosition + @SqlCheckLength < LEN(@SqlText)
BEGIN
-- 修改计数器
SET @SqlCheckLength = @SqlCheckLength + 1;
-- 获得左侧内容
SET @SqlLeftContent = LEFT(@SqlRightText, @SqlCheckLength);
-- 更新记录
UPDATE dbo.Dictionary SET count = count + 1
WHERE content = @SqlLeftContent;
-- 设置统计数值
SET @SqlStatisticCount = @SqlStatisticCount + @@ROWCOUNT;
END
END
-- 打印结果
PRINT '统计字典词频(tid=' +
CONVERT(NVARCHAR(MAX), @SqlTID) + ')> 频次统计' +
CONVERT(NVARCHAR(MAX), @SqlStatisticCount) + '次';
---- 更新数据记录
UPDATE dbo.TextPool SET parsed = parsed + 1 WHERE tid = @SqlTid;
-- 取下一条记录
FETCH NEXT FROM SqlCursor INTO @SqlTID, @SqlText;
END
-- 关闭游标
CLOSE SqlCursor;
-- 释放游标
DEALLOCATE SqlCursor;
-- 返回成功
PRINT '统计字典词频> 所有文本全部统计完毕!';
END
GO